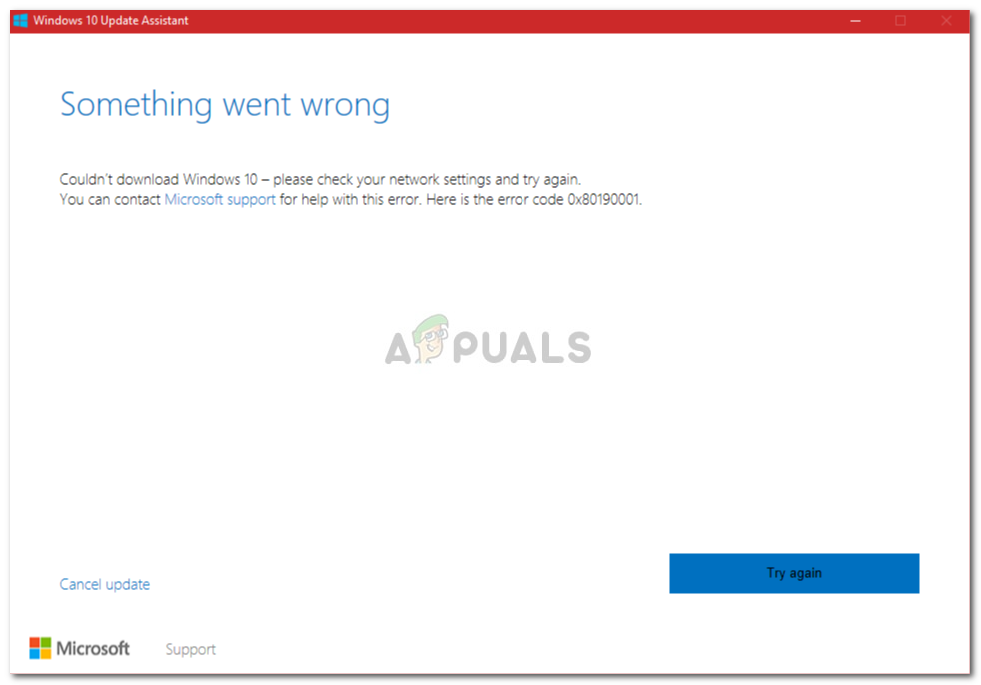
Google balss meklēšana
Google ir viens no AI pētniecības pionieriem, un daudzi viņu projekti ir pagriezuši galvu. AlfaZero no Google DeepMind komanda bija sasniegums AI pētījumos, pateicoties programmas spējai pašam apgūt sarežģītas spēles (bez cilvēka apmācības un iejaukšanās). Google arī ir paveicis lielisku darbu Dabiskās valodas apstrādes programmas (NLP), kas ir viens no Google palīga efektivitātes cēloņiem cilvēka runas izpratnē un apstrādē.
Google nesen paziņoja par trīs jaunu izlaišanu IZMANTOJIET daudzvalodu moduļus un piedāvājiet vairāk daudzvalodu modeļus semantiski līdzīga teksta izgūšanai.
Pirmie divi moduļi nodrošina daudzvalodu modeļus semantiski līdzīga teksta izgūšanai, viens optimizēts izguves veiktspējai, otrs ātrumam un mazākai atmiņas lietošanai. Trešais modelis ir specializēts jautājumu-atbilžu iegūšana sešpadsmit valodās (USE-QA), un tas ir pilnīgi jauns USE pielietojums. Visi trīs daudzvalodu moduļi tiek apmācīti, izmantojot a daudzuzdevumu divu kodētāju sistēma , līdzīgi sākotnējam USE modelim angļu valodā, vienlaikus izmantojot tehnikas, kuras mēs izstrādājām divkodētājs ar papildmargu softmax pieeju . Tie ir paredzēti ne tikai, lai uzturētu labu pārneses mācīšanās sniegumu, bet arī lai veiktu sem semantiskās izguves uzdevumus.
Valodu apstrāde sistēmās ir gājusi garu ceļu, sākot no pamata sintakses koka parsēšanas līdz lielo vektoru asociācijas modeļiem. Konteksta izpratne tekstā ir viena no lielākajām problēmām NLP laukā, un Universal Sentence Encoder to atrisina, pārveidojot tekstu augstas dimensijas vektoros, kas atvieglo teksta ranžēšanu un apzīmēšanu.

UTE marķēšanas struktūras avots - Google emuārs
Saskaņā ar Google teikto: Trīs jaunie moduļi visi ir veidoti uz semantiskās izguves arhitektūras, kas parasti jautājumu un atbilžu kodēšanu sadala atsevišķos neironu tīklos, kas ļauj meklēt miljardiem potenciālo atbilžu milisekundēs. Citiem vārdiem sakot, tas palīdz labāk indeksēt datus.
' Visi trīs daudzvalodu moduļi tiek apmācīti, izmantojot a daudzuzdevumu divu kodētāju sistēma , līdzīgi sākotnējam USE modelim angļu valodā, vienlaikus izmantojot tehnikas, kuras mēs izstrādājām divkodētājs ar papildmargu softmax pieeju . Tie ir paredzēti ne tikai, lai uzturētu labu pārneses mācīšanās sniegumu, bet arī lai veiktu sem semantiskās izguves uzdevumus . ” Funkciju Softmax bieži izmanto, lai ietaupītu skaitļošanas jaudu, eksponējot vektorus un pēc tam katru elementu dalot ar eksponenta summu.
Semantiskā izguves arhitektūra
“Visi trīs jaunie moduļi ir veidoti uz semantiskās izguves arhitektūrām, kas parasti jautājumu un atbilžu kodēšanu sadala atsevišķos neironu tīklos, kas ļauj meklēt miljardos potenciālo atbilžu milisekundēs. Divu kodētāju izmantošanas efektīvai semantiskai iegūšanai atslēga ir iepriekš kodēt visas kandidātu atbildes uz gaidāmajiem ievades vaicājumiem un saglabāt tās vektoru datu bāzē, kas ir optimizēta tuvākā kaimiņa problēma , kas ļauj ātri meklēt lielu skaitu kandidātu ar labu precizitāte un atsaukšana . '
Šos moduļus varat lejupielādēt no TensorFlow Hub. Plašāku lasījumu skatiet vietnē GoogleAI blogpost .
Tagi google